Creating a Brainfuck compiler in Golang
here is the accompanying repo with instructions on how to build and run both the compiler and the debugger if you would like to read the code (its a mess, I won’t lie) or test things out yourself.
Intro
Brainfuck is a language that has really captured the minds of programmers since it’s creation. It has overshadowed many other esoteric languages and remained the defacto standard of insane programming languages. There’s a chance that when you think of eso-langs or programming with hellish difficulty, you will immediately think of Brainfuck.
I think this is because of Brainfuck’s elegance in its simplicity. There are only 8 instructions and you can write a brainfuck compiler in pretty much any language with very minimal lines of code, or even a few bytes. Despite it being so simple, Brainfuck is Turing complete, you can feasibly solve any' programming problem in Brainfuck (no one said it wouldn’t be painful)
There are only a few instructions involved in Brainfuck:
| Instruction | Effect |
|---|---|
| ‘>’ | increment the data pointer to point to the next cell |
| ‘<’ | decrement the data pointer to point to the prior cell |
| ‘+’ | increment (increase by one) the byte at the data pointer. |
| ‘-’ | decrement (decrease by one) the byte at the data pointer. |
| ‘.’ | output the byte at the data pointer to stdout. |
| ‘,’ | accept one byte of input, storing its value in the byte at the data pointer. |
| ‘[’ | start a loop until the value under the pointer is 0 |
| ‘]’ | jump to beginning ‘[’ if the pointer value is non-zero or end the loop |
and the backing “memory” is just an array of integers, and the “pointer” just holds the current index in that array. From there, we can use the rest of our operators to read from stdin, write to stdout, increment and decrement the memory cell, shift the pointer index left or right, and create loops.
A Brainfuck program can be as simple as reading a file or string byte by byte and using a switch case to output (or emit) C or Asm code
based on the instruction, and ignoring every other character. For my case, I’m looking to go a little deeper than that.
Setting the stage
Our Brainfuck compiler will:
- compile to C
- compile to Asm
- compile to Go
- be interpreted at runtime
- have some minor optimizations (now I can call it an optimized brainfuck compiler like the big dogs)
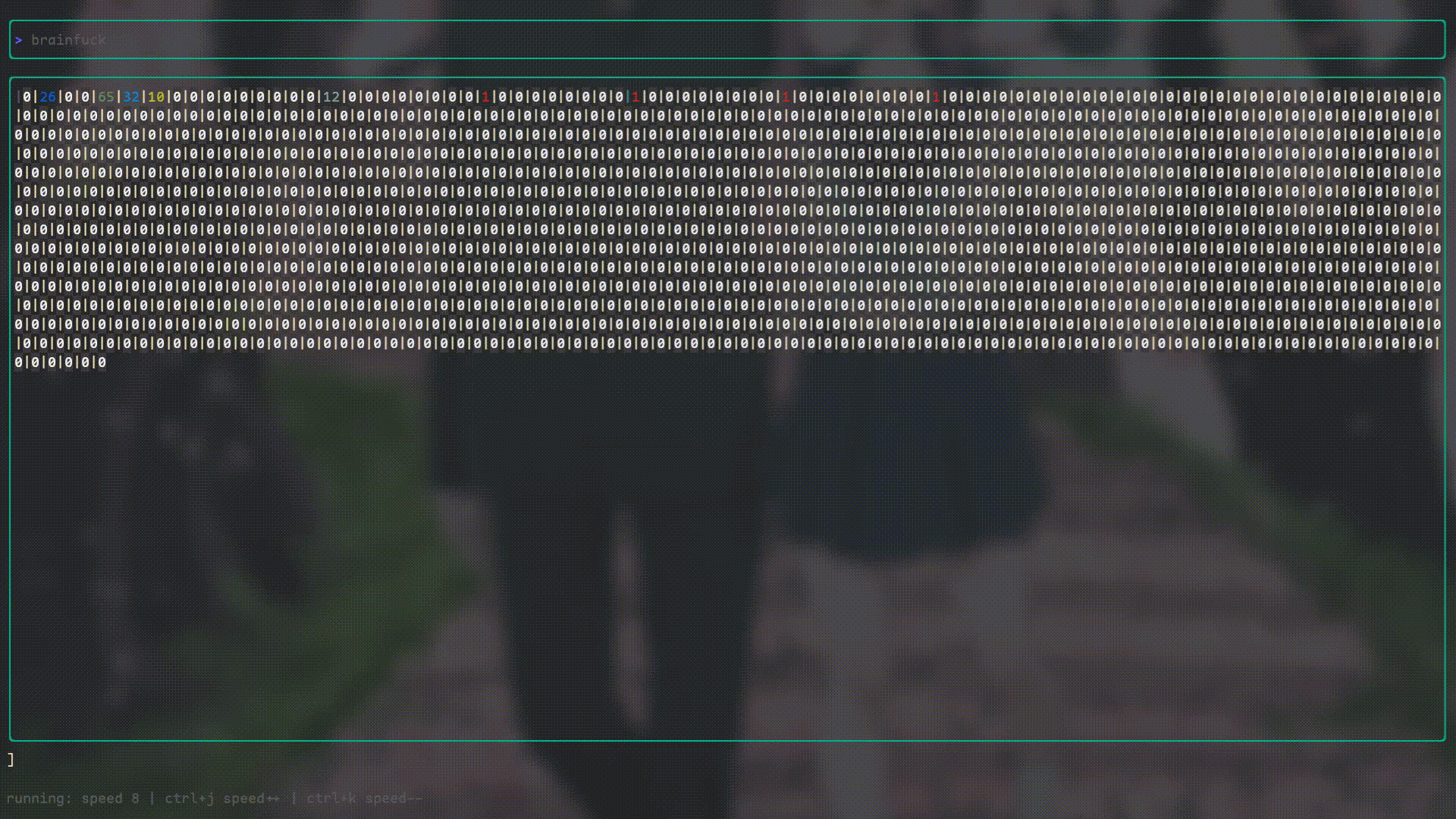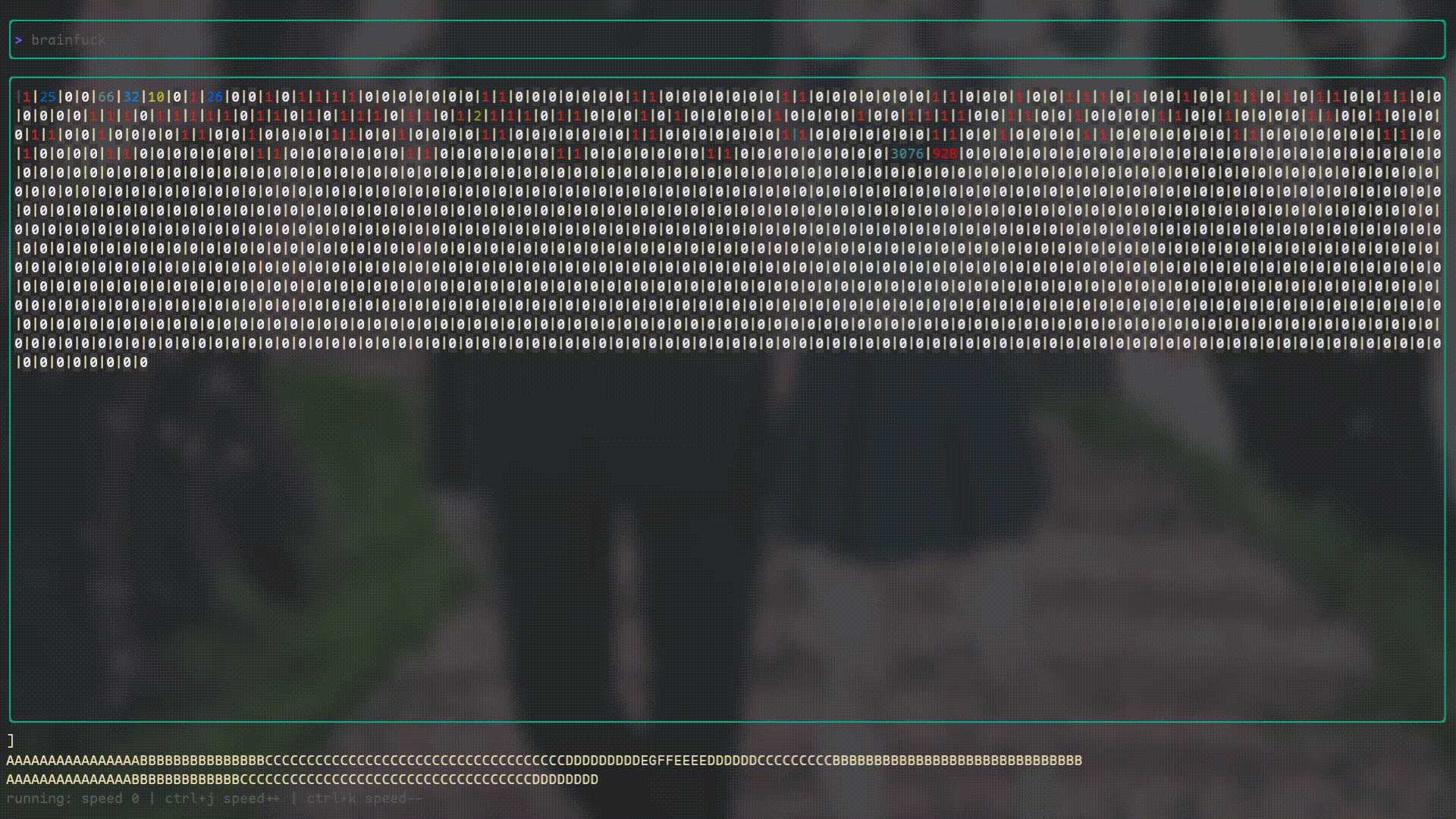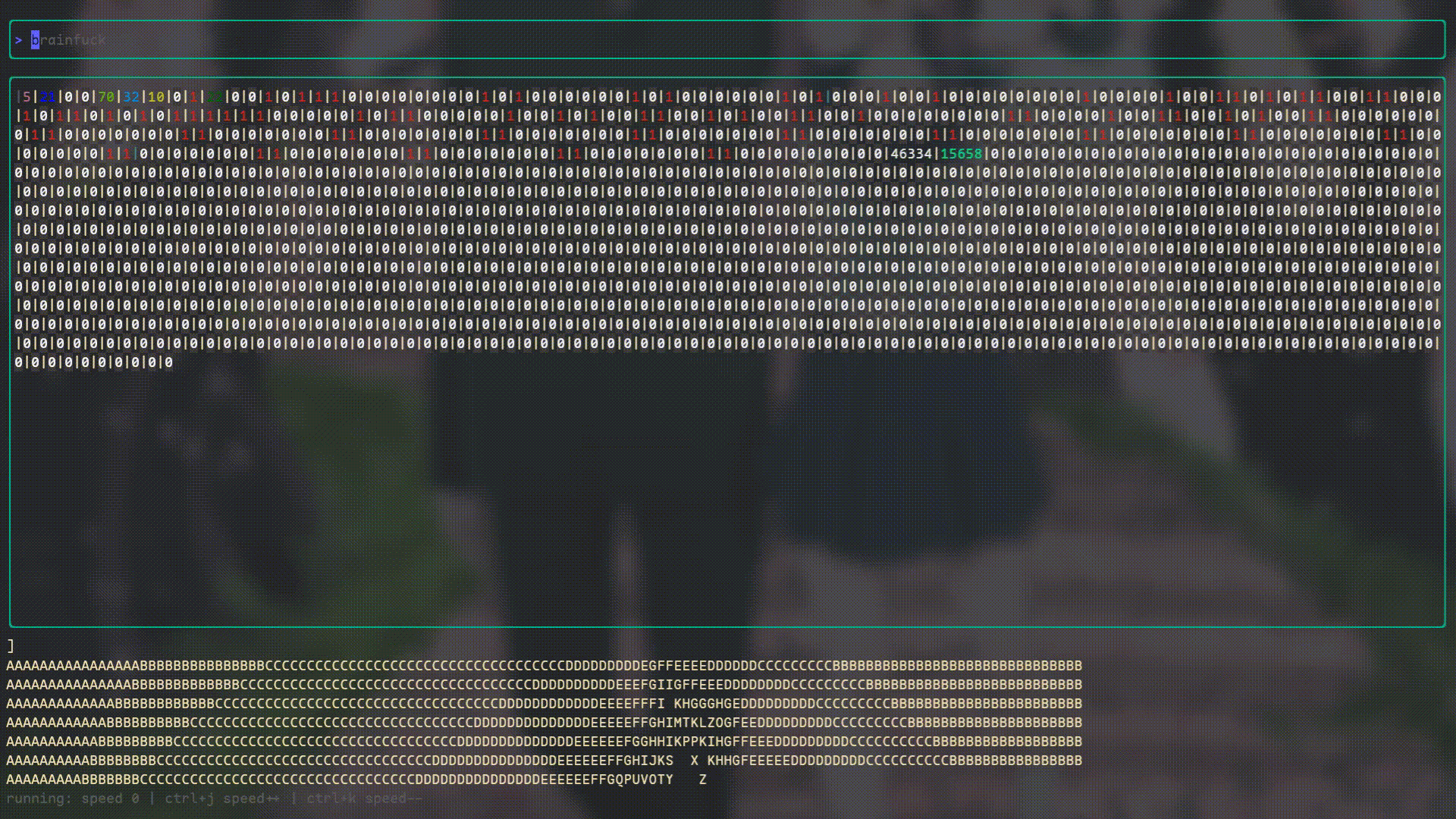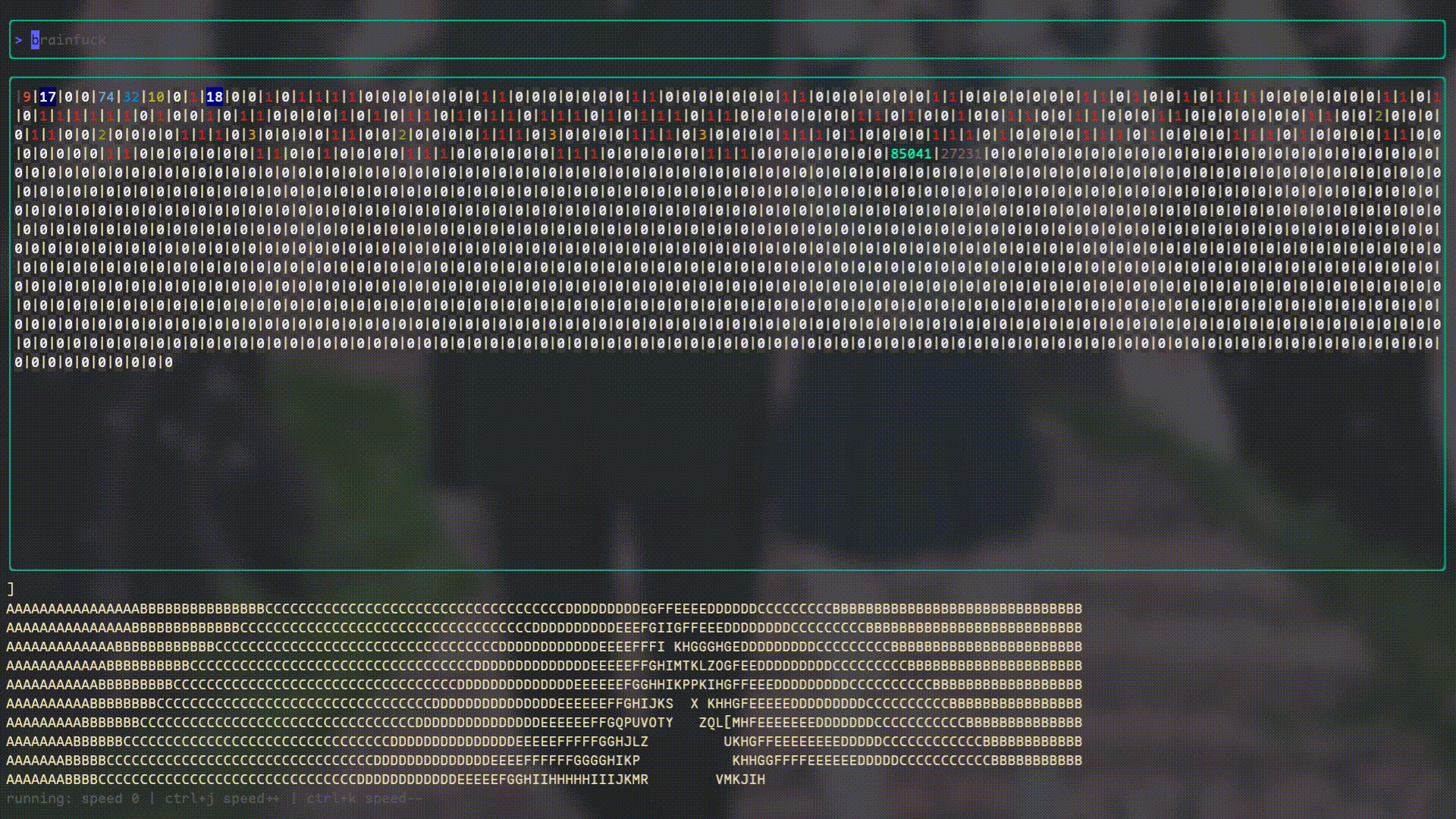
I’ve also created a “Debugger” using Bubbletea because I really wanted to see what Brainfuck’s internal state looked like while it was running. It looks like this:
The steps:
- read a Brainfuck program
- parse the input
- run some simple optimizations
- emit code as
Cand compile withgccor interpret our AST at runtime
I was surprised at just how simple this process is. I spent a lot of time thinking that compilers were just magic and that there was zero chance that I would ever understand them. In reality, its fairly simple (all things considered)
The general overview is:
- Read a raw brainfuck file into memory
- Lexing and Tokenization
- Optimization
- Code generation or interpretation
- Compilation
I’ll save you the giant blocks of code and just give you the general gist of what goes down.
There are a few “rules” we have to follow according to and succintly outlined by this gist
which I will paraphrase here:
- any token not defined must be ignored. (this is a common way of writing comments, you put them in a loop statement like ‘[blah blah blah]’)
- all memory blocks or “cells” must start as ‘0’
- loops may be infinitely nested BUT every open [ must have its corresponding closing bracket ]
the simplest brainfuck program:
[-]
which just decrements the current pointed to value, to zero. All of our cells should be zero already so this just exits without ever entering the loop.
Here is a better example… we increase the currently pointed at value to 6 and then loop over that value 6 times until that cell is equal to 0:
++++++[-]
our memory looks something like this:
# MEMORY BLOCKS, we increment 6 times
[6][0][0][0][0]...
└─memory pointer
# MEMORY BLOCKS, we loop
[0][0][0][0][0]...
└─memory pointer
which is equivalent to:
// C
char array[333];
int idx = 0;
array[idx] += 6;
while(array[idx]){
array[idx]--;
}
Here is a commented Hello, World! in Brainfuck courtesy of Wikipedia:
+++++ +++++ initialize counter (cell #0) to 10
[ use loop to set the next four cells to 70/100/30/10
> +++++ ++ add 7 to cell #1
> +++++ +++++ add 10 to cell #2
> +++ add 3 to cell #3
> + add 1 to cell #4
<<<< - decrement counter (cell #0)
]
> ++ . print 'H'
> + . print 'e'
+++++ ++ . print 'l'
. print 'l'
+++ . print 'o'
> ++ . print ' '
<< +++++ +++++ +++++ . print 'W'
> . print 'o'
+++ . print 'r'
----- - . print 'l'
----- --- . print 'd'
> + . print '!'
> . print '\n'
Lexing and optimizations
For Lexing we define our token constants, a “token” type which holds its “token literal” (thanks Thorsten Ball for writing “Writing an Interpreter in Go” its massively helpful) A nice and simple optimization here is to count how many times a token is repeated.
// token types
const (
EOF = "EOF"
DEC_PTR = "<"
INC_PTR = ">"
INC_CELL = "+"
DEC_CELL = "-"
OUTPUT = "."
INPUT = ","
LOOP_OPEN = "["
LOOP_CLOSE = "]"
)
type Token struct {
// "<" "+" etc...
Type string
// number of consecutive tokens of this type
Repeat int
}
type Lexer struct {
// the BF program
input string
// the current position the lexer points to
position int
// map of characters to their token type
known map[string]string
// lets us determine if a token can have multiple occurences
repeat map[string]bool
}
This allows us to condense +++++ from 5 instructions, down to one. This greatly
adds up over time.
in our code generation step we can simply use a printf statmement with our token.Repeat as an argument to generate the following:
// C
array[idx] += 5;
as opposed to incrementing the indexed array value five individual times:
// C
array[idx]++;
array[idx]++;
array[idx]++;
array[idx]++;
array[idx]++;
the other low-hanging optimization that we can make involves this instruction [-]. As stated above, this just decrements the current cell to 0, so if a cell
has a value of 333 it will iterate over this loop 333 times. Instead of that, we can stop at the open loop token ‘[’ and “peek” ahead to assert that the next to tokens are minus - and close loop ]In that case we can just automatically set the pointed at cell to 0 directly.
You could argue that gcc optimizes this stuff out, but you gotta remember that we are also writing an interpreter (and that we want the badge of a “self-optimizing” brainfuck compiler
because it sounds cool as fuck).
From there its as simple as spitting out C code, compiling it and running it. You can check out my code but I will show you an example from
because it gets the idea across in the simplest and shortest way possible:
while ((c = fgetc(infile)) != EOF) {
switch(c) {
case '>': fprintf(outfile, "ptr++;\n"); break;
case '<': fprintf(outfile, "ptr--;\n"); break;
case '+': fprintf(outfile, "++*ptr;\n"); break;
case '-': fprintf(outfile, "--*ptr;\n"); break;
case '[': fprintf(outfile, "while(*ptr){\n"); break;
case ']': fprintf(outfile, "}\n"); break;
case '.': fprintf(outfile, "putchar(*ptr);\n"); break;
case ',': fprintf(outfile, "*ptr=getchar();\n"); break;
}
// ...
Whereas in my case, we have the optimizations that I outlined above so it looks more like this:
for token_index < len(program) {
// the current token
tok := program[token_index]
switch tok.Type {
case lexer.INC_PTR:
buf.WriteString(fmt.Sprintf(" idx += %d;\n", tok.Repeat))
case lexer.DEC_PTR:
buf.WriteString(fmt.Sprintf(" idx -= %d;\n", tok.Repeat))
case lexer.INC_CELL:
buf.WriteString(fmt.Sprintf(" array[idx] += %d;\n", tok.Repeat))
case lexer.DEC_CELL:
buf.WriteString(fmt.Sprintf(" array[idx] -= %d;\n", tok.Repeat))
case lexer.OUTPUT:
buf.WriteString(" putchar(array[idx]);\n")
case lexer.INPUT:
buf.WriteString(" array[idx] = getchar();\n")
case lexer.LOOP_OPEN:
// our [-] optimization
if token_index+2 < len(program) {
// if the next two tokens exist (bounds check) and they are equal to - and ], set cell to 0
if program[token_index+1].Type == lexer.DEC_CELL && program[token_index+2].Type == lexer.LOOP_CLOSE {
buf.WriteString(" array[idx] = 0;")
token_index += 3
continue
}
}
buf.WriteString(" while ( array[idx] ) {\n")
case lexer.LOOP_CLOSE:
buf.WriteString("}\n")
default:
// token not handled, decide what to do here
// continue
return nil, fmt.Errorf("unhandled token: %s at index %d", tok.Type, token_index)
}
token_index++
}
Here are some benchmarks printing a Mandelbrot-set using hyperfine
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|---|---|---|---|---|
./mandelbrot-c | 512.0 ± 1.7 | 510.3 | 514.6 | 1.00 |
./mandelbrot-go | 2217.8 ± 1.2 | 2216.1 | 2219.6 | 4.33 ± 0.01 |
./bfcc mandelbrot.bf | 13572.8 ± 154.1 | 13347.0 | 13808.8 | 26.51 ± 0.31 |
as you could guess C with gcc optimizations is by far the fastest, Go comes in second, and interpreted is the slowest (it genuinely doesn’t feel that slow in general suprisingly enough)
for gcc I used:
gcc -static -O3 -s -o "${output}" "${output}.c"
for go I used:
go build -ldflags='-s -w' -o "${output}" "${output}.go"
